[JAVA]集合
集合类
集合跟数组一样,可以表示同样的一组元素,但是他们的相同和不同之处在于:
- 它们都是容器,都能够容纳一组元素。
不同点:
- 1.数组的大小是固定的,集合的大小是可变的。
- 2.数组可以存放基本数据类型,但集合只能存放对象。
集合类的根接口
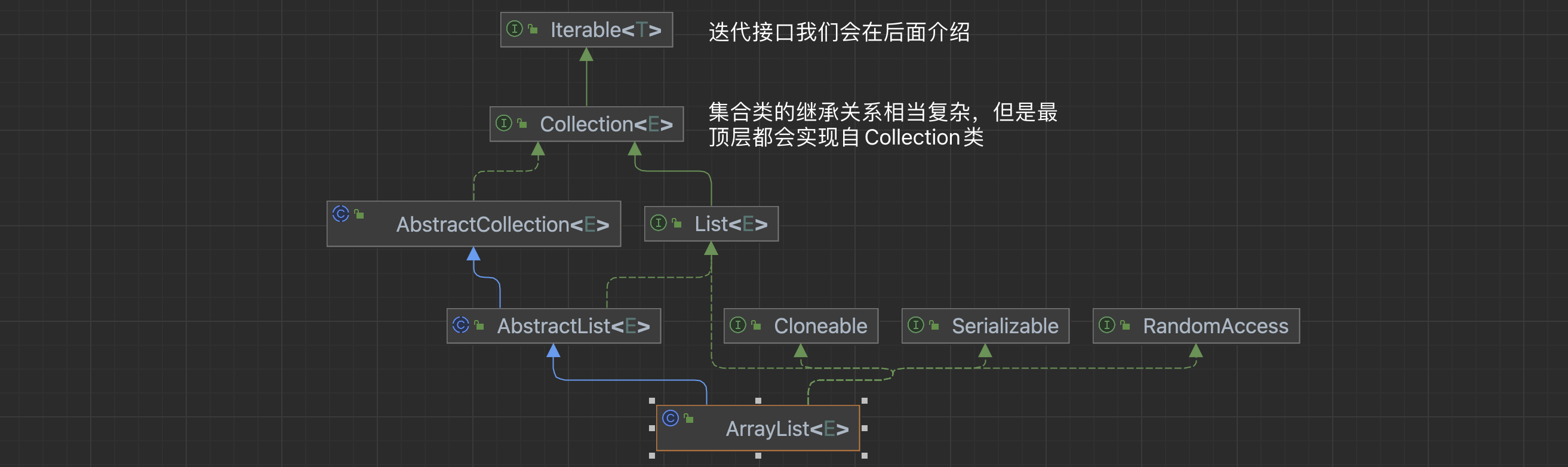
- ArrayList的祖先就是Collection接口。
List列表
- List列表(线性表),支持随机访问。
List是集合类型的一个分支,它的主要特性有: - 是一个有序的集合,插入元素默认是插入到尾部,按顺序从前往后存放,每个元素都有一个自己的下表。
- 列表中国运行存在重复元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74//List是一个有序的集合类,每个元素都有一个自己的下标位置
//List中可插入重复元素
//针对于这些特性,扩展了Collection接口中一些额外的操作
public interface List<E> extends Collection<E> {
...
//将给定集合中所有元素插入到当前结合的给定位置上(后面的元素就被挤到后面去了,跟我们之前顺序表的插入是一样的)
boolean addAll(int index, Collection<? extends E> c);
...
//Java 8新增方法,可以对列表中每个元素都进行处理,并将元素替换为处理之后的结果
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator(); //这里同样用到了迭代器
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
//对当前集合按照给定的规则进行排序操作,这里同样只需要一个Comparator就行了
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
...
//-------- 这些是List中独特的位置直接访问操作 --------
//获取对应下标位置上的元素
E get(int index);
//直接将对应位置上的元素替换为给定元素
E set(int index, E element);
//在指定位置上插入元素,就跟我们之前的顺序表插入是一样的
void add(int index, E element);
//移除指定位置上的元素
E remove(int index);
//------- 这些是List中独特的搜索操作 -------
//查询某个元素在当前列表中的第一次出现的下标位置
int indexOf(Object o);
//查询某个元素在当前列表中的最后一次出现的下标位置
int lastIndexOf(Object o);
//------- 这些是List的专用迭代器 -------
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator();
//迭代器我们会在下一个部分讲解
ListIterator<E> listIterator(int index);
//------- 这些是List的特殊转换 -------
//返回当前集合在指定范围内的子集
List<E> subList(int fromIndex, int toIndex);
...
}ArrayList
在ArrayList中,底层采用数组来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
//默认的数组容量
private static final int DEFAULT_CAPACITY = 10;
...
//存放数据的底层数组,这里的transient关键字我们会在后面I/O中介绍用途
transient Object[] elementData;
//记录当前数组元素数的
private int size;
//这是ArrayList的其中一个构造方法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity]; //根据初始化大小,创建当前列表
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
...
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 这里会判断容量是否充足,不充足需要扩容
elementData[size++] = e;
return true;
}
...
//默认的列表最大长度为Integer.MAX_VALUE - 8
//JVM都C++实现中,在数组的对象头中有一个_length字段,用于记录数组的长
//度,所以这个8就是存了数组_length字段(这个只做了解就行)
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩容规则跟我们之前的是一样的,也是1.5倍
if (newCapacity - minCapacity < 0) //要是扩容之后的大小还没最小的大小大,那么直接扩容到最小的大小
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0) //要是扩容之后比最大的大小还大,需要进行大小限制
newCapacity = hugeCapacity(minCapacity); //调整为限制的大小
elementData = Arrays.copyOf(elementData, newCapacity); //使用copyOf快速将内容拷贝到扩容后的新数组中并设定为新的elementData底层数组
}
}一般的,如果我们使用一个集合类,我们会使用接口的引用:
1
2
3
4
5
6
7public static void main(String[] args) {
List<String> list = new ArrayList<>(); //使用接口的引用来操作具体的集合类实现,是为了方便日后如果我们想要更换不同的集合类实现,而且接口中本身就已经定义了主要的方法,所以说没必要直接用实现类
list.add("科技与狠活"); //使用add添加元素
list.add("上头啊");
System.out.println(list); //打印集合类,可以得到一个非常规范的结果
}在使用Integer时,呀注意传参问题:
1
2
3
4
5
6
7public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(10); //添加Integer的值10
list.remove((Integer) 10); //注意,不能直接用10,默认情况下会认为传入的是int类型值,删除的是下标为10的元素,我们这里要删除的是刚刚传入的值为10的Integer对象
System.out.println(list); //可以看到,此时元素成功被移除
}LinkedList
- LinkedList同样时List的实现类,是使用链表的。
- 是一个双向链表,也就是同时保存两个方向:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
//引用首结点
transient Node<E> first;
//引用尾结点
transient Node<E> last;
//构造方法,很简单,直接创建就行了
public LinkedList() {
}
...
private static class Node<E> { //内部使用的结点类
E item;
Node<E> next; //不仅保存指向下一个结点的引用,还保存指向上一个结点的引用
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
...
}
迭代器
通过迭代器,我们就可以实现对集合中的元素进行比阿里,就像我们遍历数组那样,运作机制大概是:
一个新的迭代器就像上面这样,默认有一个指向集合中第一个元素的指针:

每一次next操作,都会将指针后移译为,直到完成每一个元素的比那里。
- 此时再调用next将不能再得到下一个元素。
- 在调用next方法之前,迭代器的执政只想当前元素的前一个位置,而不是第一个元素。
为什么要这样设计:集合类的实现方案有很多,可能是链式粗处也有可能是数组存储,不同的实现有着不同的遍历方式,而迭代器则可以将多种多样不同的集合类遍历方式进行统一,只需要各个集合类格局自己的情况进行实现就行了。
迭代器接口的源码定义的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public interface Iterator<E> {
//看看是否还有下一个元素
boolean hasNext();
//遍历当前元素,并将下一个元素作为待遍历元素
E next();
//移除上一个被遍历的元素(某些集合不支持这种操作)
default void remove() {
throw new UnsupportedOperationException("remove");
}
//对剩下的元素进行自定义遍历操作
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}在ArrayList和LinkedList中,迭代器的实现也不同。
ArrayList是直接按下标访问的:
1
2
3
4
5public E next() {
...
cursor = i + 1; //移动指针
return (E) elementData[lastRet = i]; //直接返回指针所指元素
}LinkeList就是不断向后寻找节点:
1
2
3
4
5
6public E next() {
...
next = next.next; //向后继续寻找结点
nextIndex++;
return lastReturned.item; //返回结点内部存放的元素
}- 虽然这两种列表的实现不同,遍历方式也不同,但是都是按照迭代器的标准进行了实现。
- 我们想要遍历一个集合中所有的元素,那么就可以直接使用迭代器完成,而不需要关心集合类是如何实现。
- 注意,迭代器的使用是一次性的,用了之后就不能用了。
- 如果需要再次进行便利操作,那么需要重写生成一个迭代器对象。
Iterable接口
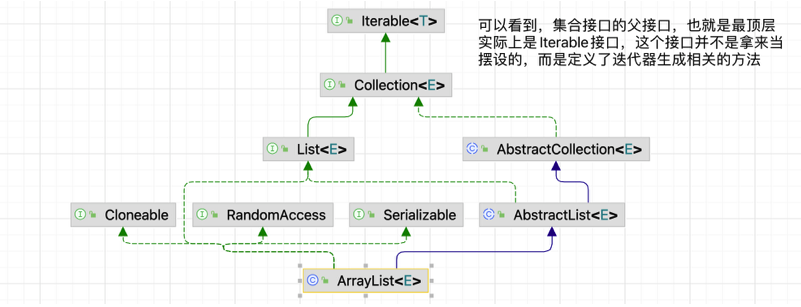
1 | //注意这个接口是集合接口的父接口,不要跟之前的迭代器接口搞混了 |
ListIterator接口
1 | public interface ListIterator<E> extends Iterator<E> { |
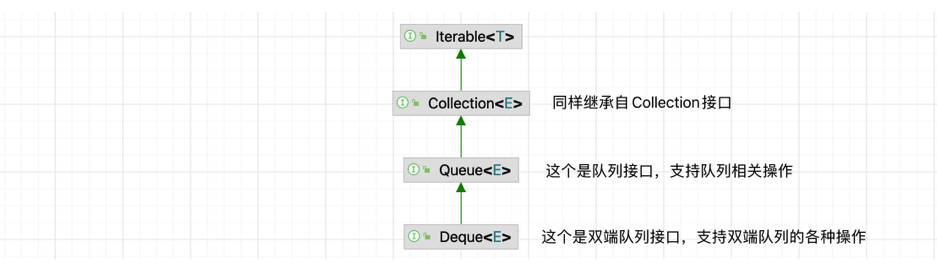
Queue和Deque
- LInkList除了可以直接当做列表使用之外,还可以直接当做其他的数据结构使用。
- 可以看到它不仅仅实现了List接口:这个Deque接口是干嘛的呢?我们先来看看它的继承结构:
1
2
3
4public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
Queue
- 队列接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public interface Queue<E> extends Collection<E> {
//队列的添加操作,是在队尾进行插入(只不过List也是一样的,默认都是尾插)
//如果插入失败,会直接抛出异常
boolean add(E e);
//同样是添加操作,但是插入失败不会抛出异常
boolean offer(E e);
//移除队首元素,但是如果队列已经为空,那么会抛出异常
E remove();
//同样是移除队首元素,但是如果队列为空,会返回null
E poll();
//仅获取队首元素,不进行出队操作,但是如果队列已经为空,那么会抛出异常
E element();
//同样是仅获取队首元素,但是如果队列为空,会返回null
E peek();
}
Dueque
双端队列就是队列的升级版,我们一个普通的队列就是:
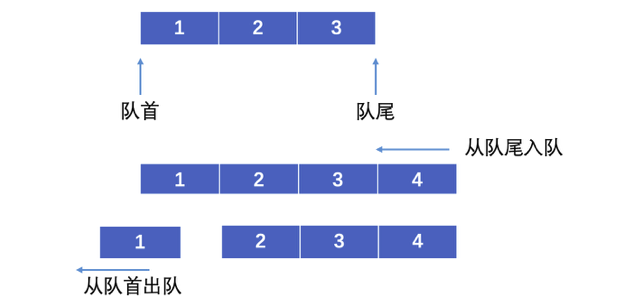
普通队列中从队尾入队,队首出队,而双端队列允许在队列的两端进行入队和出队操作:
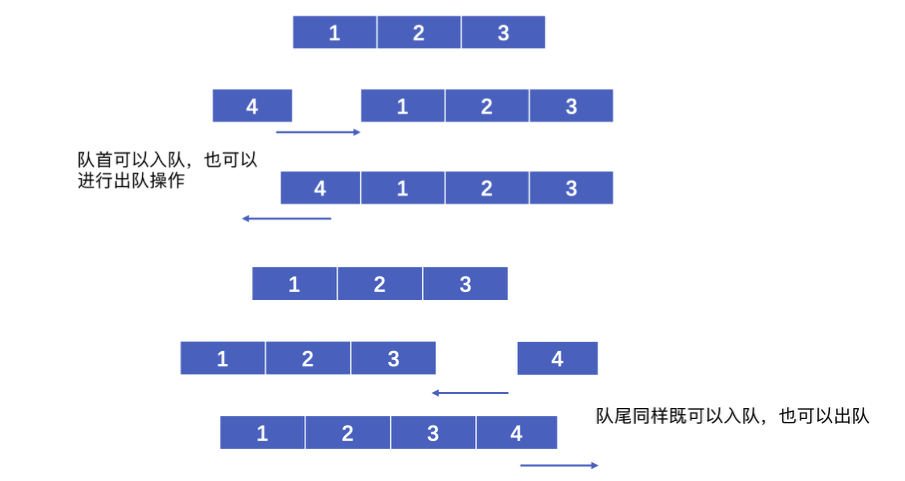
用这种特性,双端队列既可以当做普通队列使用,也可以当做栈来使用,我们来看看Java中是如何定义的Deque双端队列接口的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59//在双端队列中,所有的操作都有分别对应队首和队尾的
public interface Deque<E> extends Queue<E> {
//在队首进行插入操作
void addFirst(E e);
//在队尾进行插入操作
void addLast(E e);
//不用多说了吧?
boolean offerFirst(E e);
boolean offerLast(E e);
//在队首进行移除操作
E removeFirst();
//在队尾进行移除操作
E removeLast();
//不用多说了吧?
E pollFirst();
E pollLast();
//获取队首元素
E getFirst();
//获取队尾元素
E getLast();
//不用多说了吧?
E peekFirst();
E peekLast();
//从队列中删除第一个出现的指定元素
boolean removeFirstOccurrence(Object o);
//从队列中删除最后一个出现的指定元素
boolean removeLastOccurrence(Object o);
// *** 队列中继承下来的方法操作是一样的,这里就不列出了 ***
...
// *** 栈相关操作已经帮助我们定义好了 ***
//将元素推向栈顶
void push(E e);
//将元素从栈顶出栈
E pop();
// *** 集合类中继承的方法这里也不多种介绍了 ***
...
//生成反向迭代器,这个迭代器也是单向的,但是是next方法是从后往前进行遍历的
Iterator<E> descendingIterator();
}
SET
定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public interface Set<E> extends Collection<E> {
// Set集合中基本都是从Collection直接继承过来的方法,只不过对这些方法有更加特殊的定义
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
//添加元素只有在当前Set集合中不存在此元素时才会成功,如果插入重复元素,那么会失败
boolean add(E e);
//这个同样是删除指定元素
boolean remove(Object o);
boolean containsAll(Collection<?> c);
//同样是只能插入那些不重复的元素
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
//这个方法我们同样会放到多线程中进行介绍
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}
}
- 不允许出现重复元素。
- 不支持随机访问。
HashSET
- 底层是采用哈希表实现的。
- 我们无法维持插入元素的顺序。
- 需要维护顺序则使用LinkedHasSet。
- 排序使用TreeSet。
内部维护了一个HashMAP。
MAP
MAP接口中的一些操作
//Map并不是Collection体系下的接口,而是单独的一个体系,因为操作特殊
//这里需要填写两个泛型参数,其中K就是键的类型,V就是值的类型,比如上面的学生信息,ID一般是int,那么键就是Integer类型的,而值就是学生信息,所以说值是学生对象类型的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69public interface Map<K,V> {
//-------- 查询相关操作 --------
//获取当前存储的键值对数量
int size();
//是否为空
boolean isEmpty();
//查看Map中是否包含指定的键
boolean containsKey(Object key);
//查看Map中是否包含指定的值
boolean containsValue(Object value);
//通过给定的键,返回其映射的值
V get(Object key);
//-------- 修改相关操作 --------
//向Map中添加新的映射关系,也就是新的键值对
V put(K key, V value);
//根据给定的键,移除其映射关系,也就是移除对应的键值对
V remove(Object key);
//-------- 批量操作 --------
//将另一个Map中的所有键值对添加到当前Map中
void putAll(Map<? extends K, ? extends V> m);
//清空整个Map
void clear();
//-------- 其他视图操作 --------
//返回Map中存放的所有键,以Set形式返回
Set<K> keySet();
//返回Map中存放的所有值
Collection<V> values();
//返回所有的键值对,这里用的是内部类Entry在表示
Set<Map.Entry<K, V>> entrySet();
//这个是内部接口Entry,表示一个键值对
interface Entry<K,V> {
//获取键值对的键
K getKey();
//获取键值对的值
V getValue();
//修改键值对的值
V setValue(V value);
//判断两个键值对是否相等
boolean equals(Object o);
//返回当前键值对的哈希值
int hashCode();
...
}
...
}MAP总共无法添加相同的键,同样的键只能存在一个,即使值不同。如果出现键相同的情况,那么会覆盖掉之前的。
- HaspMAP底层使用哈希表来实现。不维护顺序,我们在获取所有键和所有值时,可能会是乱序的。
- 如果需要维护顺序,可以使用LinkedHashMap,它的内部对插入顺序进行了维护。
HashMAP
- 底层:
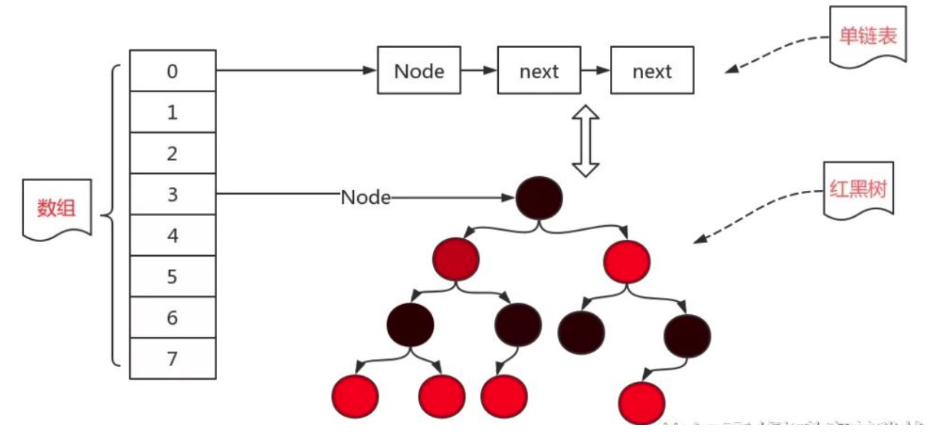
实际上这个表就是一个存放头结点的数组+若干结点,而HashMap也是这样的,我们来看看这里面是怎么定义的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
static class Node<K,V> implements Map.Entry<K,V> { //内部使用结点,实际上就是存放的映射关系
final int hash;
final K key; //跟我们之前不一样,我们之前一个结点只有键,而这里的结点既存放键也存放值,当然计算哈希还是使用键
V value;
Node<K,V> next;
...
}
...
transient Node<K,V>[] table; //这个就是哈希表本体了,可以看到跟我们之前的写法是一样的,也是头结点数组,只不过HashMap中没有设计头结点(相当于没有头结点的链表)
final float loadFactor; //负载因子,这个东西决定了HashMap的扩容效果
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; //当我们创建对象时,会使用默认的负载因子,值为0.75
}
...
}可以看到,实际上底层大致结构跟我们之前学习的差不多,只不过多了一些特殊的东西:
- HashMap支持自动扩容,哈希表的大小并不是一直不变的,否则太过死板
- HashMap并不是只使用简单的链地址法,当链表长度到达一定限制时,会转变为效率更高的红黑树结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88public V put(K key, V value) {
//这里计算完键的哈希值之后,调用的另一个方法进行映射关系存放
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) //如果底层哈希表没初始化,先初始化
n = (tab = resize()).length; //通过resize方法初始化底层哈希表,初始容量为16,后续会根据情况扩容,底层哈希表的长度永远是2的n次方
//因为传入的哈希值可能会很大,这里同样是进行取余操作
//(n - 1) & hash 等价于 hash % n 这里的i就是最终得到的下标位置了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); //如果这个位置上什么都没有,那就直接放一个新的结点
else { //这种情况就是哈希冲突了
Node<K,V> e; K k;
if (p.hash == hash && //如果上来第一个结点的键的哈希值跟当前插入的键的哈希值相同,键也相同,说明已经存放了相同键的键值对了,那就执行覆盖操作
((k = p.key) == key || (key != null && key.equals(k))))
e = p; //这里直接将待插入结点等于原本冲突的结点,一会直接覆盖
else if (p instanceof TreeNode) //如果第一个结点是TreeNode类型的,说明这个链表已经升级为红黑树了
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //在红黑树中插入新的结点
else {
for (int binCount = 0; ; ++binCount) { //普通链表就直接在链表尾部插入
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); //找到尾部,直接创建新的结点连在后面
if (binCount >= TREEIFY_THRESHOLD - 1) //如果当前链表的长度已经很长了,达到了阈值
treeifyBin(tab, hash); //那么就转换为红黑树来存放
break; //直接结束
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //同样的,如果在向下找的过程中发现已经存在相同键的键值对了,直接结束,让p等于e一会覆盖就行了
break;
p = e;
}
}
if (e != null) { // 如果e不为空,只有可能是前面出现了相同键的情况,其他情况e都是null,所有直接覆盖就行
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; //覆盖之后,会返回原本的被覆盖值
}
}
++modCount;
if (++size > threshold) //键值对size计数自增,如果超过阈值,会对底层哈希表数组进行扩容
resize(); //调用resize进行扩容
afterNodeInsertion(evict);
return null; //正常插入键值对返回值为null
}
- 如果底层哈希表没有初始化,先初始化。
- 默认长度为16,后会扩容,底层哈希表的长度永远为2的n次方。
- 如果已经初始化,取余存值。
- 哈希冲突:哈希值相同。
- 如果键相同,直接覆盖。
- 键不相同,链表插入。
- 链表超过8,变成红黑树。
- 红黑树插入。
- 节点数量超过阈值,对哈希数组进行扩容。通过resize()进行扩容。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //先把下面这几个旧的东西保存一下
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0; //这些是新的容量和扩容阈值
if (oldCap > 0) { //如果旧容量大于0,那么就开始扩容
if (oldCap >= MAXIMUM_CAPACITY) { //如果旧的容量已经大于最大限制了,那么直接给到 Integer.MAX_VALUE
threshold = Integer.MAX_VALUE;
return oldTab; //这种情况不用扩了
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //新的容量等于旧容量的2倍,同样不能超过最大值
newThr = oldThr << 1; //新的阈值也提升到原来的两倍
}
else if (oldThr > 0) // 旧容量不大于0只可能是还没初始化,这个时候如果阈值大于0,直接将新的容量变成旧的阈值
newCap = oldThr;
else { // 默认情况下阈值也是0,也就是我们刚刚无参new出来的时候
newCap = DEFAULT_INITIAL_CAPACITY; //新的容量直接等于默认容量16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //阈值为负载因子乘以默认容量,负载因子默认为0.75,也就是说只要整个哈希表用了75%的容量,那么就进行扩容,至于为什么默认是0.75,原因很多,这里就不解释了,反正作为新手,这些都是大佬写出来的,我们用就完事。
}
...
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; //将底层数组变成新的扩容之后的数组
if (oldTab != null) { //如果旧的数组不为空,那么还需要将旧的数组中所有元素全部搬到新的里面去
... //详细过程就不介绍了
}
}
LinkHaspMAP
- 维护插入顺序。
- 继承自HahpMAP。具有HashMap的全部性质,同时得益于每一个节点都是一个双向链表,在插入键值对时,同时保存了插入顺序。
1
2
3
4
5
6static class Entry<K,V> extends HashMap.Node<K,V> { //LinkedHashMap中的结点实现
Entry<K,V> before, after; //这里多了一个指向前一个结点和后一个结点的引用
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
TreeMAP
- ,它的内部直接维护了一个红黑树(没有使用哈希表)因为它会将我们插入的结点按照规则进行排序,所以说直接采用红黑树会更好,我们在创建时,直接给予一个比较规则即可,跟之前的TreeSet是一样的:
1
2
3
4
5
6
7public static void main(String[] args) {
Map<Integer , String> map = new TreeMap<>((a, b) -> b - a);
map.put(0, "单走");
map.put(1, "一个六");
map.put(3, "**");
System.out.println(map);
}